
The Personal Health Stack
The stack is almost built. Where the AI opportunity in healthcare sits.


Every technology wave produces a stack. The personal health stack is being built right now and the highest-value layer isn’t chips or foundation models. It’s the Tier 5 interface layer: the point closest to the patient, where fragmented health data gets compiled into actionable clinical decisions. Delphi-2M is the clearest proof of why.
The model that can predict your diseases
In 2025, a new model called Delphi-2M was launched. Developed by Torkamani et al. at the Scripps Research Institute and published in Nature, trained on hundreds of thousands of records, it predicts the probability you’ll develop any of 1,000+ diseases (up to 20 years before symptoms appear).
It doesn’t need a new scan or a new test. It needs your existing data, compiled. Most of us don’t have it. That is one problem I’ll talk about.
This isn’t new, as Laura Rosales noted in a past ConteNido deep dive that most wearable data never makes it to the clinical side.
The Stack
Last month I came across this piece by Elliot Hershberg in Century of Biology and it reframed how I was thinking about the whole personal health opportunity.

His argument: the underappreciated bet in AI isn’t the headline model. It’s the infrastructure every company needs regardless of who wins. That framing stuck with me because in personal health the same logic applies, just inverted.
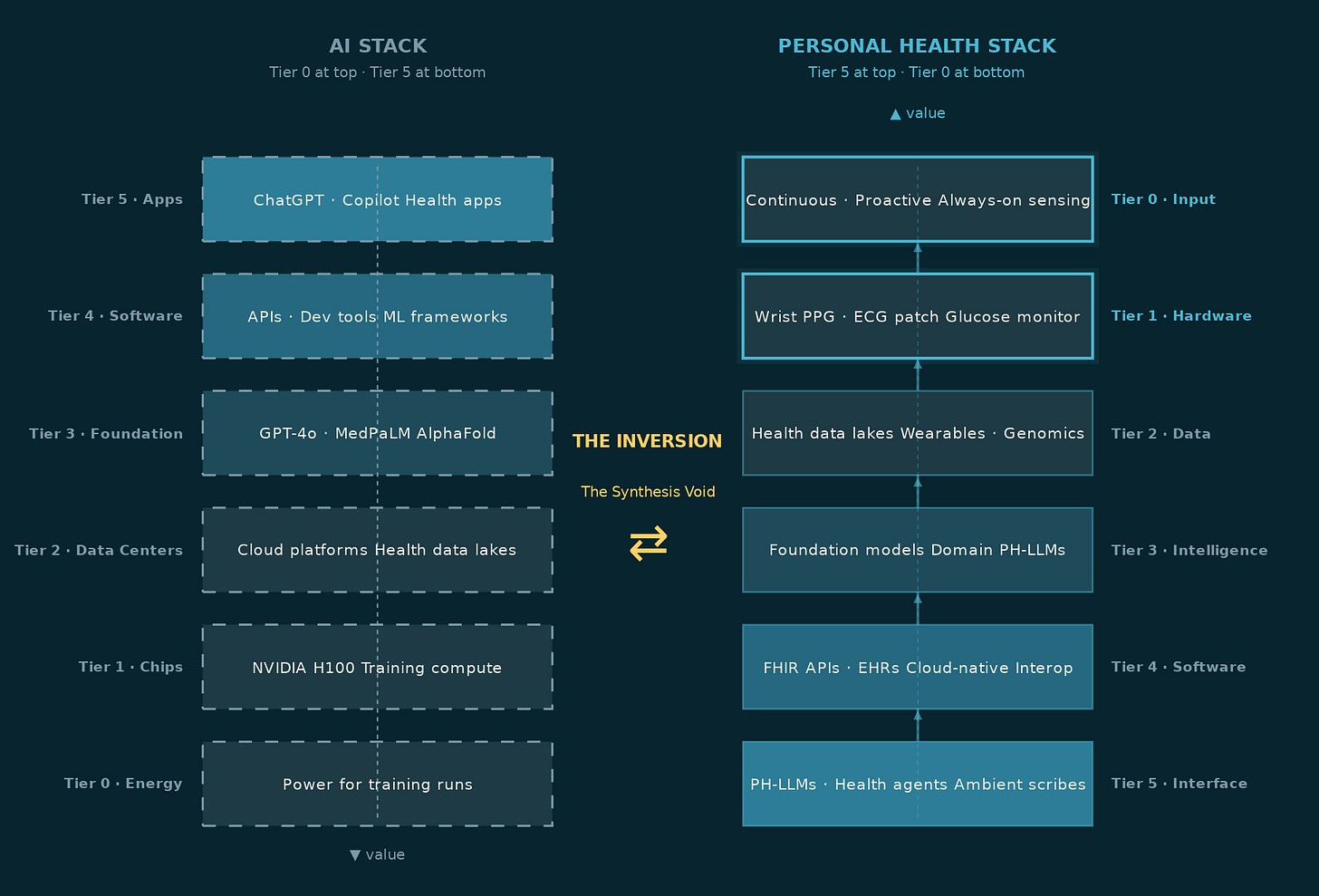
In the general AI stack, the enabling layer sits at the bottom. Every application, every chatbot, every recommendation engine, every copilot depends on the compute, data centers, and foundation models below it. Hershberg applied this logic to drug discovery: the underappreciated bet isn’t the drug that wins, it’s the infrastructure every drug company needs regardless of who wins.
In personal health, that logic inverts. The chips exist. The cloud exists. The foundation models are largely built. What doesn’t exist yet, at any meaningful scale, is the Tier 5 interface layer at the top, the one that takes a person’s fragmented health signals: a wearable stream, a lab result, a medic note from three years ago, and compiles them into something coherent. Something a doctor can act on in a twelve-minute consultation. Something a patient can open on a Tuesday morning and actually understand.
That layer is Tier 5. And before it can exist, the data has to exist.
The Data Problem
The base for every AI model is the data it is built on. In personal health, that data has always been difficult to access, scattered across the existing Electronic Health Records (EHRs), labs, wearables, and GP notes that rarely talk to each other.
Before the Tier 5 interface layer can do any of its work, the data has to be portable, accurate, and structured.
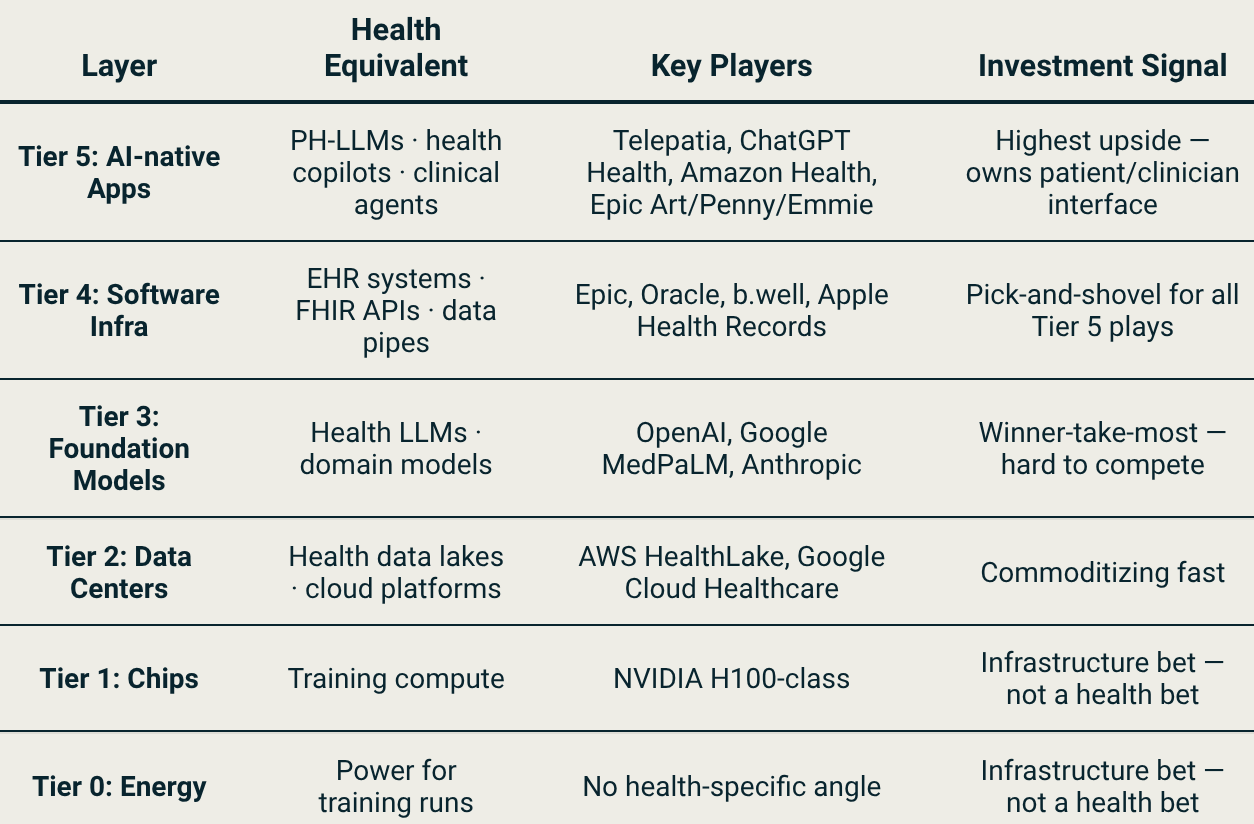
Think about what happens when you switch doctors. You fill out the same forms again. You repeat the same medical history. Your new medic has no idea what your last one prescribed, what your bloodwork looked like three years ago, or that you already tried the medication they’re about to suggest. That’s not a technical problem, it’s a political one. Hospitals, insurers, and EHR vendors had every financial incentive to keep your data locked inside their systems. Your records were their asset, not yours. Three regulatory moves are changing that simultaneously, as demonstrated by the table below.

The 21st Century Cures Act turned health data portability into a legal requirement in the US, hospitals and EHR vendors can no longer block a patient’s access to their own records. That’s the pipe ChatGPT Health and Amazon Connect Health are already running on. Europe mandates the same thing in 2029. LATAM is building the pipes from scratch, as Nido Venture’s Telepatia AI is building upon, to capitalize on the fragmented options.
In the last few months, model providers such as OpenAI, Anthropic, and Amazon (crazy, since they pulled out of wearables and health hardware in 2023) have started pulling existing EHR data available in the US to bring more accurate data to patients. This was made possible by the 21st Century Cures Act. Though not without data privacy concerns.
The blood sample you take was standardized in the 1950s, and they’ve proven accurate enough that nobody rushed to replace them. But that’s the point. We don’t need a new needle. We need a model that can connect a 1950s style glucose reading to a 2026 style wearable stream and tell you something neither could say alone. The innovation was never going to be the test. It’s the Tier 5 interface layer above it.
Data in personal health compounds the same way search data is compounded for Google. Jason Kelly, CEO of Ginkgo Bioworks, made the parallel explicit in a 2021 Business Breakdowns episode on Moderna:
Google has 25 years of search data to train their algorithms and you don’t. Whoever’s got the most wins.
His point was about synthetic biology. Once you think of DNA as code, the lab that has run the most experiments owns the most valuable training set on earth. The same logic applies to personal health AI: the equivalent compounding asset isn’t search queries, it’s longitudinal patient records: labs, wearable streams, consultation notes, genomics accumulated over years. The platform that builds that data pipeline first doesn’t just have a better model today. It has a wall that gets higher every day it stays in production.
The same infrastructure gaps as we documented in CRISPR Cas9: Editing the Future are the ones the most interesting Tier 4/5 players in clinical AI are navigating today.
The Stack and Human Meeting Point
At HIMSS 2026 in Las Vegas (the conference that sets the clinical technology agenda every year), Tier 5 stopped being a roadmap slide. Every major player showed up with a named product and a live deployment.
Epic: Art (clinical notes), Penny (billing and coverage denials), Emmie (patient scheduling and triage).
Oracle: Clinical AI Agent across 30 specialties, ambient listening in real time. AtlantiCare reported a 41% reduction in documentation time across all emergency departments. Over 200,000 hours of documentation saved across the US in just over a year.
Amazon: Amazon Connect Health five agents covering patient intake, scheduling, and ambient voice documentation, with native Epic integration
Microsoft: Dragon Copilot, embedded directly into existing clinical workflows, with UpToDate’s clinical knowledge base injected as a hallucination guardrail.
The interesting part isn't that they shipped. It's that they shipped before the evidence base caught up. Agents are already sitting in exam rooms, drafting records, and assessing patients while most healthcare systems still don't have the benchmarks to evaluate them properly. Google learned this the hard way when they pulled AI health summaries in January 2026 after incorrect information surfaced to users. The intelligence layer is moving faster than the evidence layer. That gap is the risk nobody is pricing in yet.
On the consumer side, OpenAI and Anthropic chose opposite ends of the same layer. ChatGPT Health targets the patient, explaining lab results, interpreting wearable data, and preparing questions for appointments. Claude for Healthcare targets the clinician, cutting prior authorization paperwork, connecting to ICD-10 and CMS databases, reducing administrative overhead. Same stack layer. Opposite doors into the healthcare system.
But even when Tier 5 exists and works, it doesn’t automatically get used. Personal health has already proven that more data without synthesis produces one thing: a dashboard nobody opens. The tools that survive are the ones that behave like an editor not a feed: suppressing noise, asking one question, delivering one next step. The ones that don’t are forgotten by month two.
When AI Learns to Read your Body
In 2024, Baker and Hassabis won ½ of the Nobel Prize in Chemistry for AlphaFold — a model that predicted the 3D structure of over 200 million proteins, compared to the approx. 170,000 prior researchers had managed to characterize. Hassabis took the same logic into drug discovery with Isomorphic Labs, where the next bottleneck isn’t the model anymore, it’s the trials.
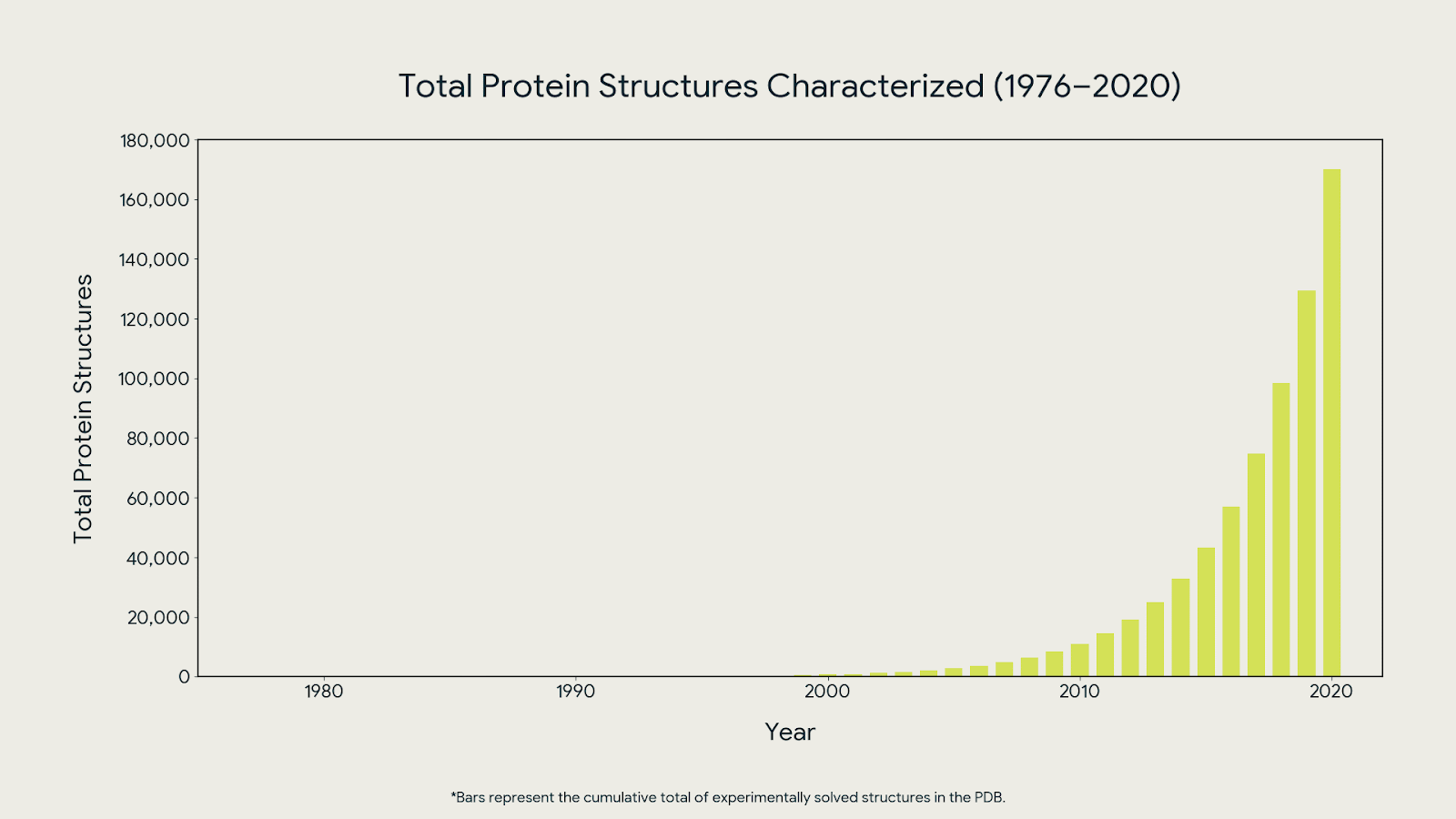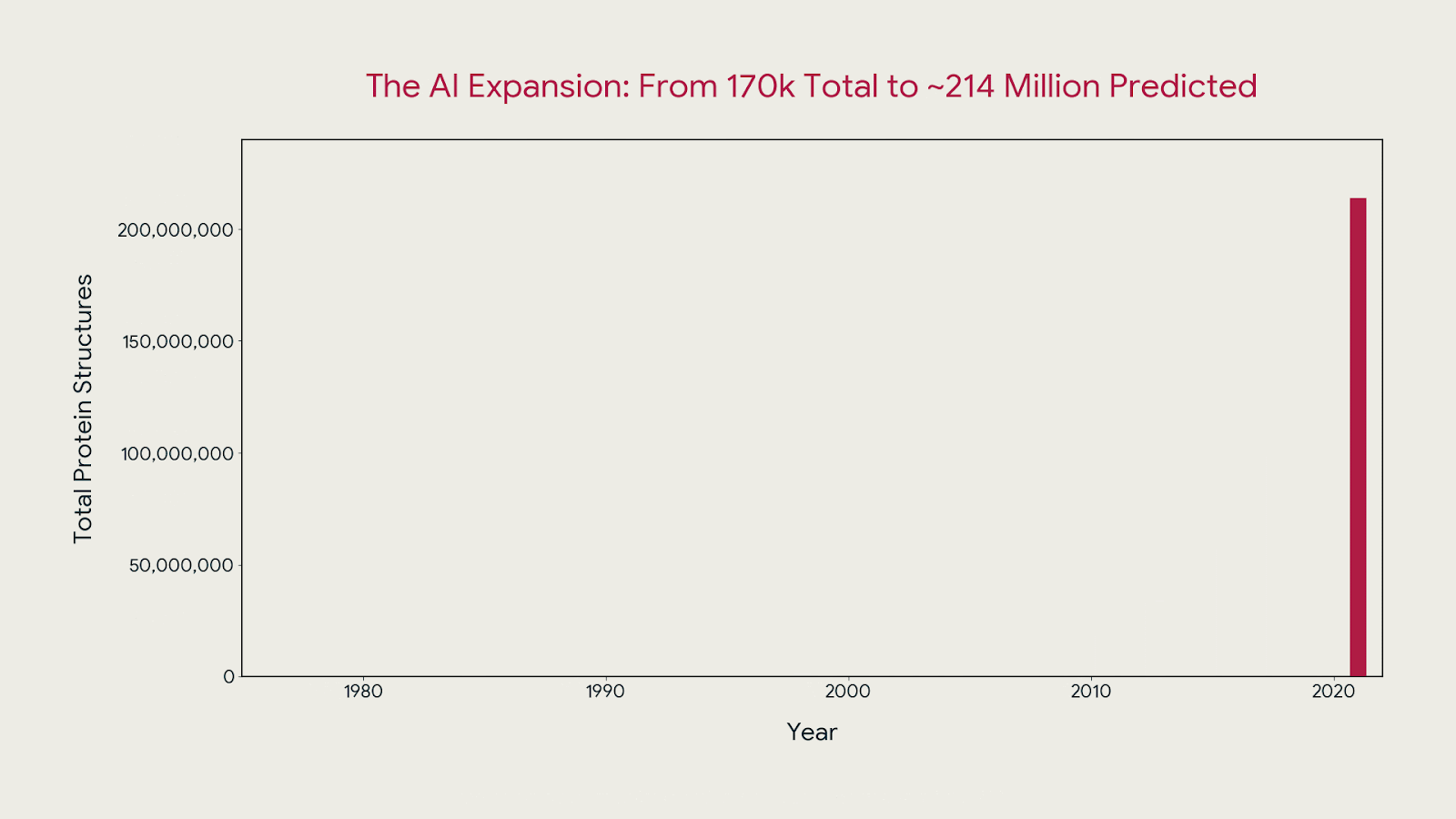
The shift of applying AI to an existing dataset, producing insight no human process could match at scale is now beginning in personal health. The difference is that proteins are static. Your health timeline is not.
And while AlphaFold solved the static problem of protein folding, the dynamic problem of human health requires the data pipes described in the section above. That’s the bridge between regulation and intelligence and it’s the reason Tier 5 can’t exist without Tier 4.
Five research groups published architectures in 2025–2026 that show what this intelligence layer looks like in practice:
Delphi-2M: Trained on hundreds of thousands of longitudinal records, predicting 1,000+ diseases up to 20 years before symptoms appear. It doesn’t need a new scan. It needs compiled data, which is exactly the problem.
PHIA: The first LLM agent to answer personal health questions using passive wearable data alone. No visit, no new test — just the stream your device already captures.
Domain PH-LLMs: Narrow models trained specifically on sleep and fitness data outperformed general LLMs on personal health tasks. Specialization beats scale.
Google PH-LLM + LSM: A Gemini model fine-tuned for health, paired with a Large Sensor Model trained on the largest wearable dataset ever compiled. Three coordinated agents: one reads the data, one verifies against clinical sources, one turns the findings into a single next step. Tested on 1,200 real users, it outperformed single models across every benchmark.
Singapore Agentic Pilot: A small-scale pilot of a multi-agent system generating iterative preventive health plans with a clinician in the loop. AI as analyst, doctor as final call.
None of them need new hardware. None of them need a new blood test. They need the data that already exists: compiled, structured, portable. That’s precisely why the regulatory moves matter.
That’s also when the FDA question comes in. By February 2026, over 1,400 AI-enabled devices had been cleared (with radiology still dominating at around 75% of all clearances), including Apple’s hypertension and sleep apnea detection from wrist PPG, and Anumana’s ECG-AI, which takes a standard electrocardiogram and detects heart failure risk a doctor would have missed entirely. The FDA evaluates these on four criteria: cybersecurity and data quality, model type (locked vs. adaptive), intended clinical use, and post-market surveillance requirements. The framework is rigorous. But the intelligence layer is moving faster than the clearance calendar, and that gap is widening.
Who Owns the Stack
OpenAI bet on the patient (consumer SaaS, high volume, low touch). Anthropic bet on the clinician (enterprise, workflow-embedded, HIPAA-compliant). Neither is wrong, as they reflect each company’s existing distribution strength. But neither of them are the ones writing the biggest checks.
And the market is responding. NVIDIA’s 2026 Healthcare AI Survey found that 70% of respondents said their organizations are already actively using AI, while 85% said their AI budgets will increase this year. For hospitals, insurers, and provider networks (the segment that writes the biggest checks), the top AI use case isn’t diagnostics or drug discovery. It’s administrative tasks and workflow optimization. 47% said optimizing AI workflows and production cycles is one of their top spending priorities in 2026. The organizations writing the checks are the ones already inside the system: hospital groups, insurance networks, and EHR platforms. The startups are building the intelligence. The incumbents are buying the distribution. Not the other way around.
The winner in this space won’t be the best model. It will be whoever earns the right to sit inside the workflow, embedded deep enough that replacing them means retraining the entire clinical team. That’s a switching cost the best SaaS product in the world can’t replicate. The moat isn’t the algorithm. It’s the trust.
The Layer That Changes Everything
Delphi-2M can predict your disease risk 20 years out. The intelligence exists. What doesn’t exist yet (at any meaningful scale) is the Tier 5 interface layer that delivers it to a real person, in a real consultation, in a language they can act on.
In the near term: fragmented players at every layer, regulation still being written, engagement problems largely unsolved. In the medium term: one or two platforms that manage to combine the data portability of Tier 4, the intelligence of Tier 3, and a Tier 5 interface that someone actually opens every day. In the US that might be a BigTech company. In Europe, EHDS mandates data portability but doesn’t pick a winner. In LATAM, it might be a company most people haven’t heard of yet, building the stack in a market where the stack didn’t exist.
The model already knows. The stack just needs to catch up.